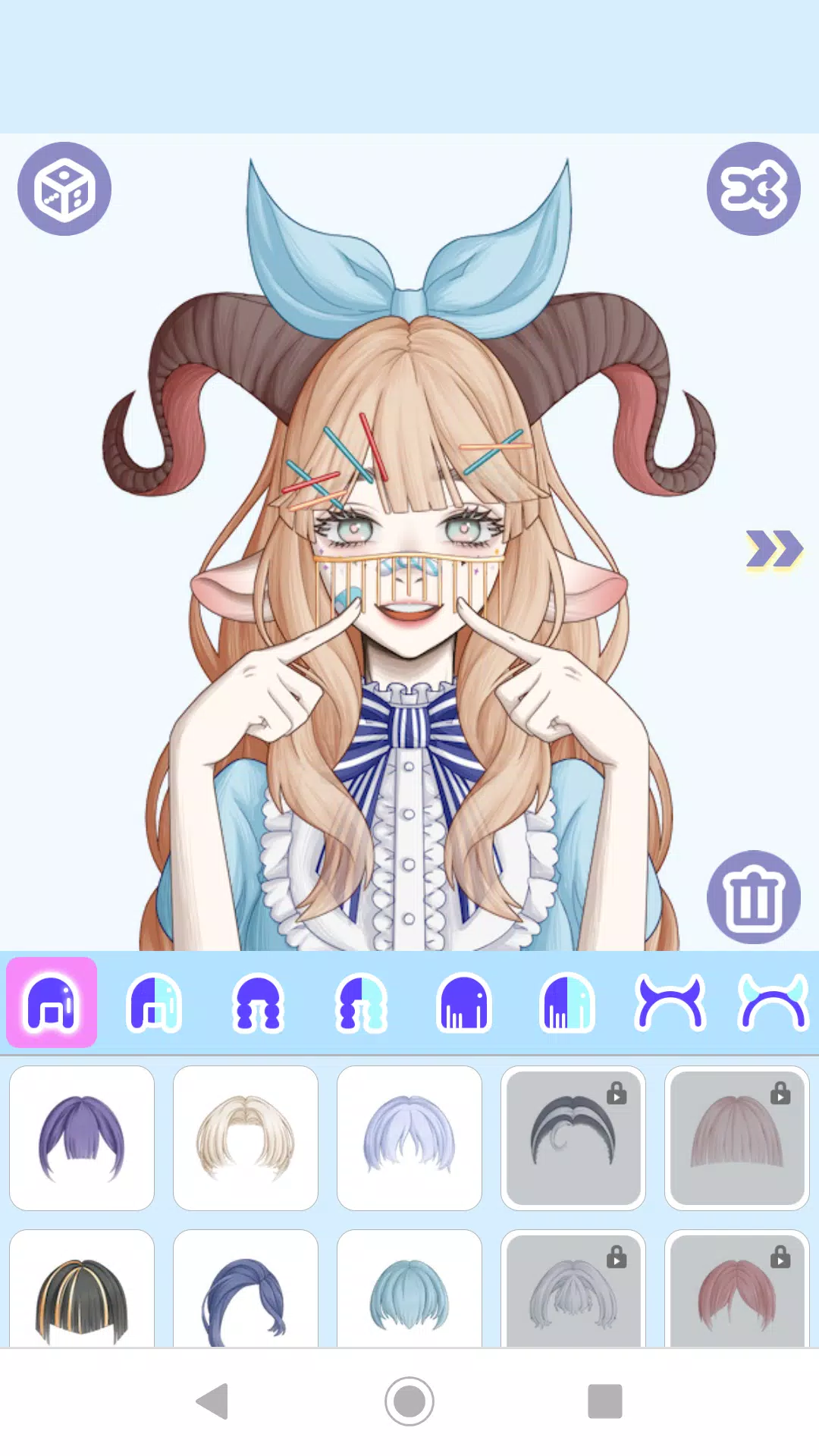
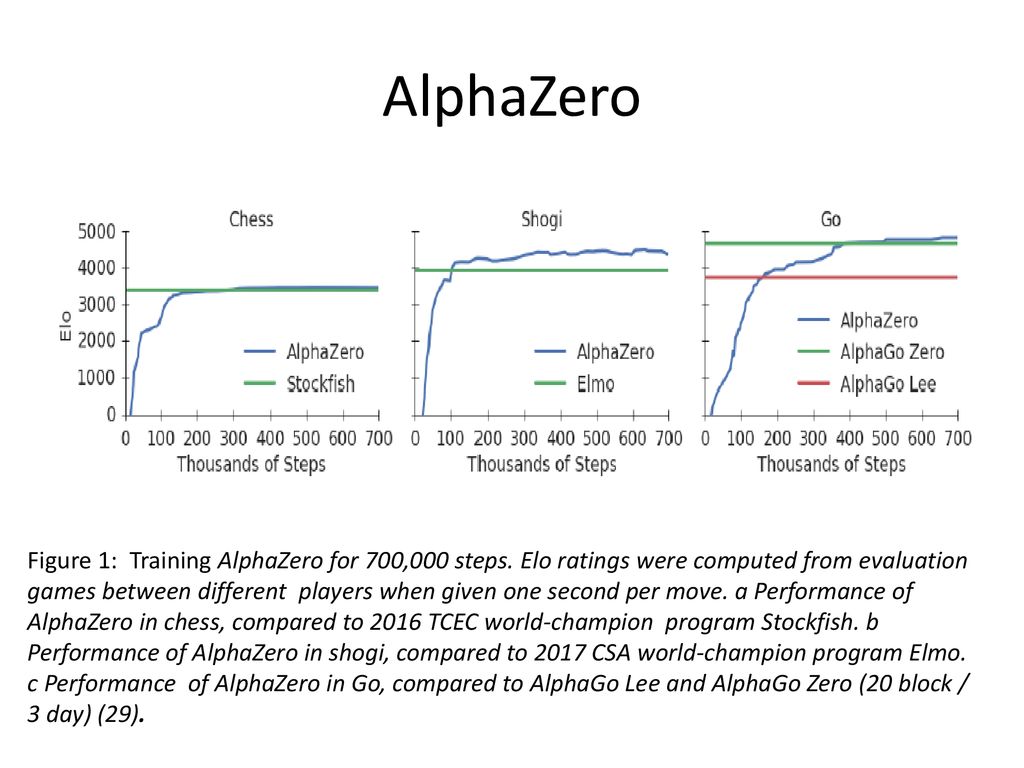
Training AlphaZero for 700,000 steps. Elo ratings were computed
Por um escritor misterioso
Descrição

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines
Gamifying Strategy - Enterprise AI use cases on agent-based simulation and reinforcement learning

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Training AlphaZero for 700,000 steps. Elo ratings were computed from

AlphaZero really is that good
How deep can an alpha zero chess think? - Quora
Function approximation - ppt download
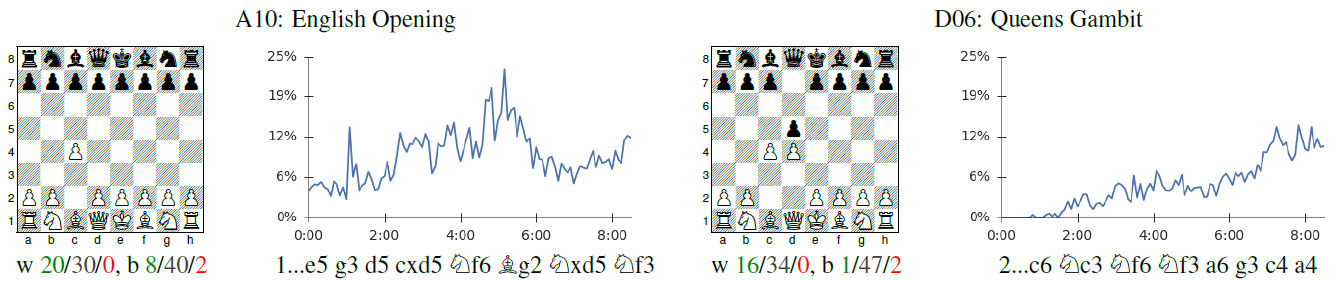
The future is here – AlphaZero learns chess

A summary of the DeepMind's general reinforcement learning algorithm, AlphaZero, by Umer Hasan
de
por adulto (o preço varia de acordo com o tamanho do grupo)




/media/movies/covers/2022/07/Q4vPA_4c.jpg)