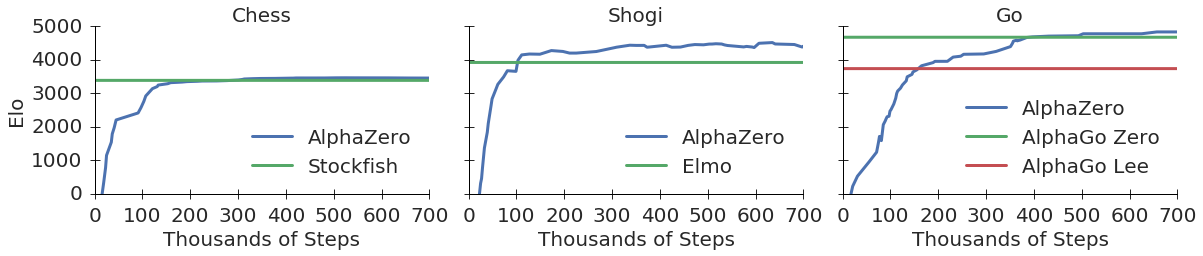
Training AlphaZero for 700,000 steps. Elo ratings were computed from
Por um escritor misterioso
Descrição

Checkmate for Traditional Chess? - Nekst-Online

From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning
AI - Last Year Progress (2018-2019)

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Generally capable agents emerge from open-ended play - Google DeepMind

Training AlphaZero for 700,000 steps. Elo ratings were computed from

Are there any ways to calculate the rating difference between AlphaGo Zero and Leela Zero? · Issue #2576 · leela-zero/leela-zero · GitHub

Training AlphaZero for 700,000 steps. Elo ratings were computed from

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines

Science Magazine - December 7, 2018 - A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

AlphaZero: Four Hours to World Class from a Standing Start - Breakfast Bytes - Cadence Blogs - Cadence Community
de
por adulto (o preço varia de acordo com o tamanho do grupo)