AGI Alignment Experiments: Foundation vs INSTRUCT, various Agent
Por um escritor misterioso
Descrição
Here’s the companion video: Here’s the GitHub repo with data and code: Here’s the writeup: Recursive Self Referential Reasoning This experiment is meant to demonstrate the concept of “recursive, self-referential reasoning” whereby a Large Language Model (LLM) is given an “agent model” (a natural language defined identity) and its thought process is evaluated in a long-term simulation environment. Here is an example of an agent model. This one tests the Core Objective Function
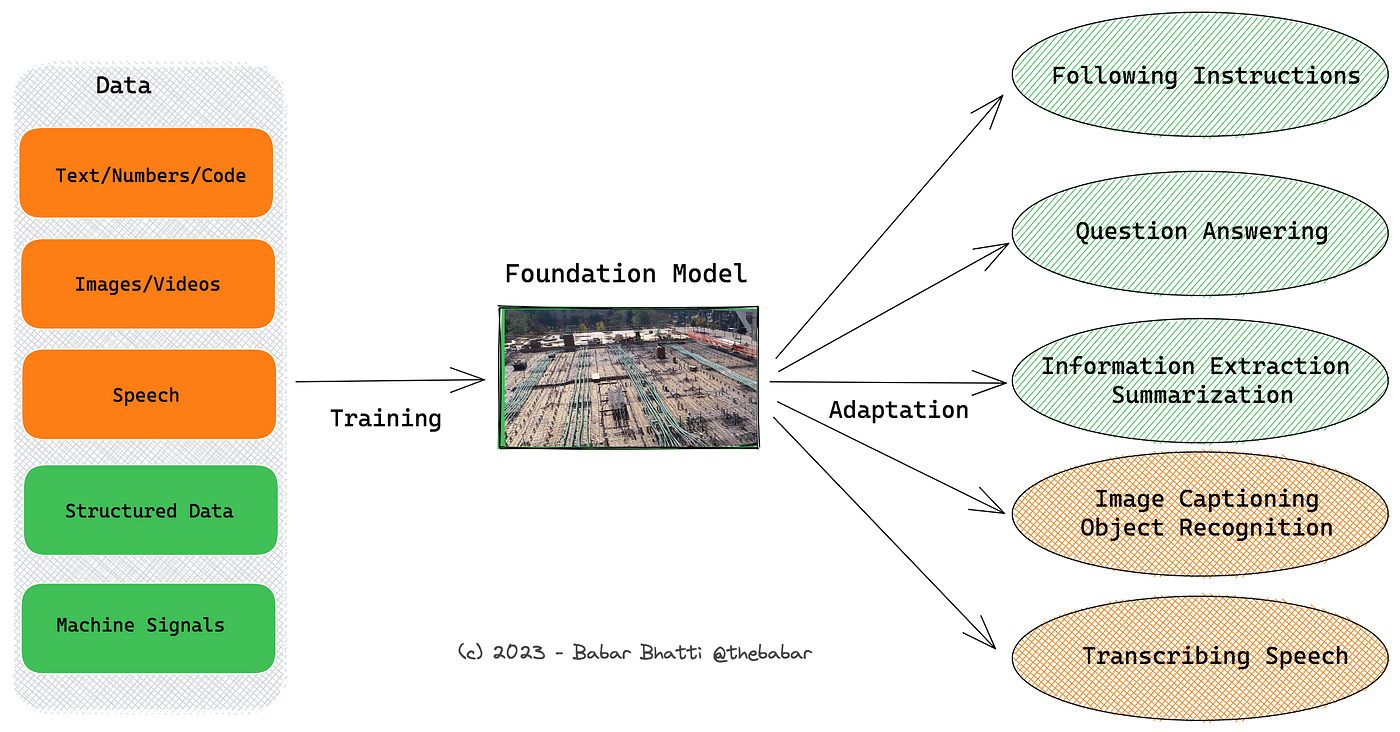
Essential Guide to Foundation Models and Large Language Models, by Babar M Bhatti
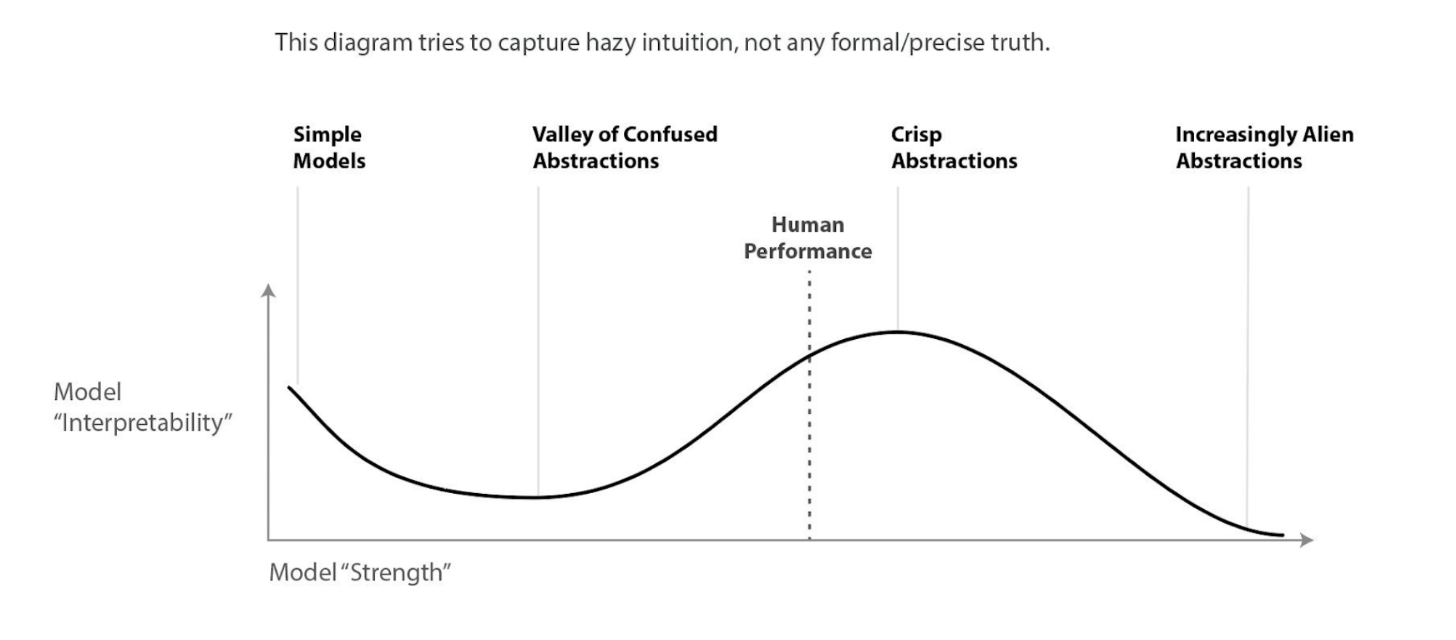
My understanding of) What Everyone in Technical Alignment is Doing and Why — AI Alignment Forum
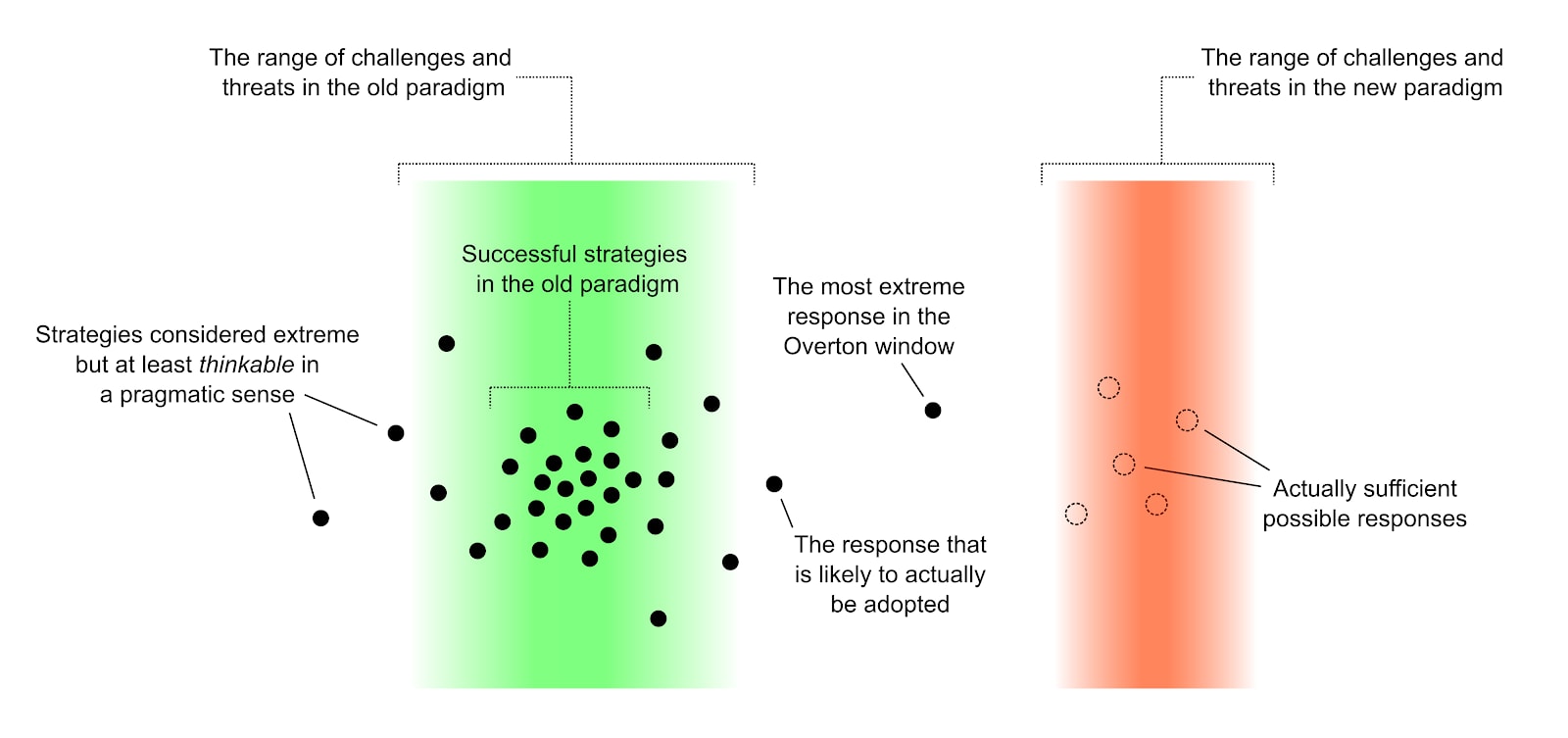
Six Dimensions of Operational Adequacy in AGI Projects — AI Alignment Forum

Auto-GPT: Unleashing the power of autonomous AI agents
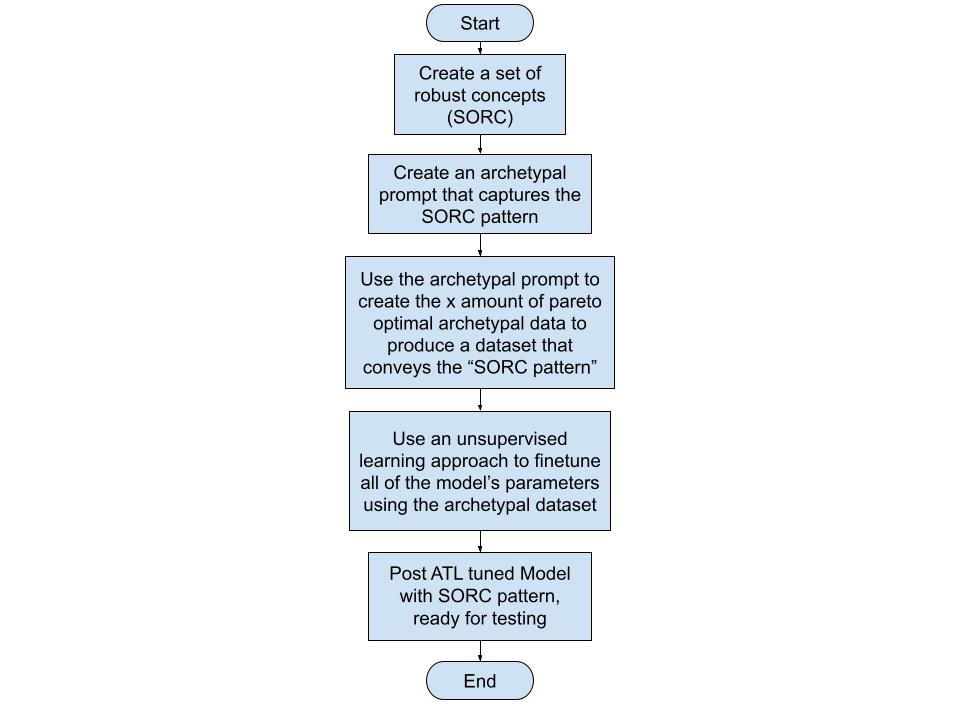
The Multidisciplinary Approach to Alignment (MATA) and Archetypal Transfer Learning (ATL) — EA Forum

PDF) Metaverse: A Solution to the Multi-Agent Value Alignment Problem

What Does It Mean to Align AI With Human Values?
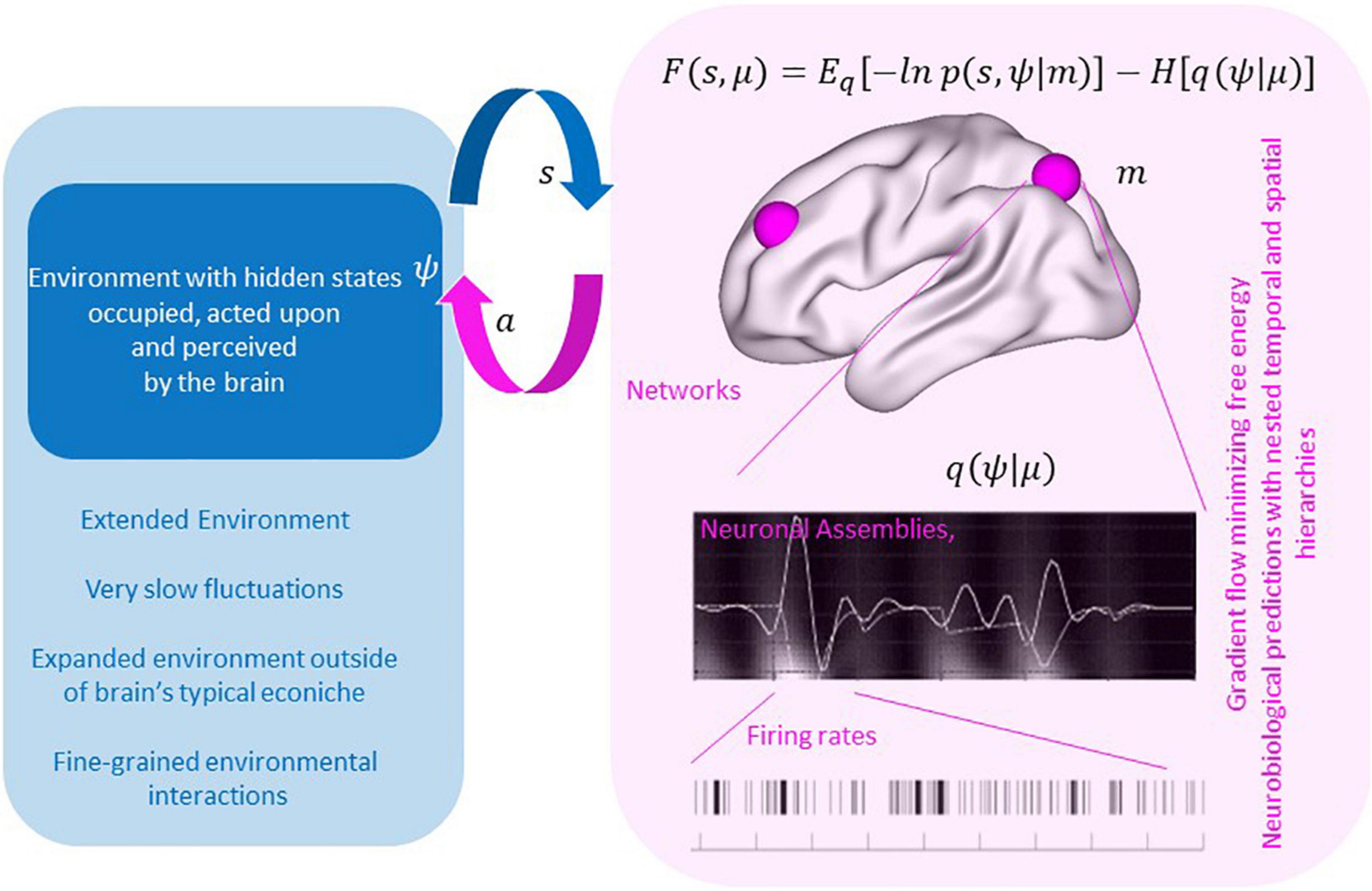
Frontiers Augmenting Human Selves Through Artificial Agents – Lessons From the Brain

A High-level Overview of Large Language Models - Borealis AI
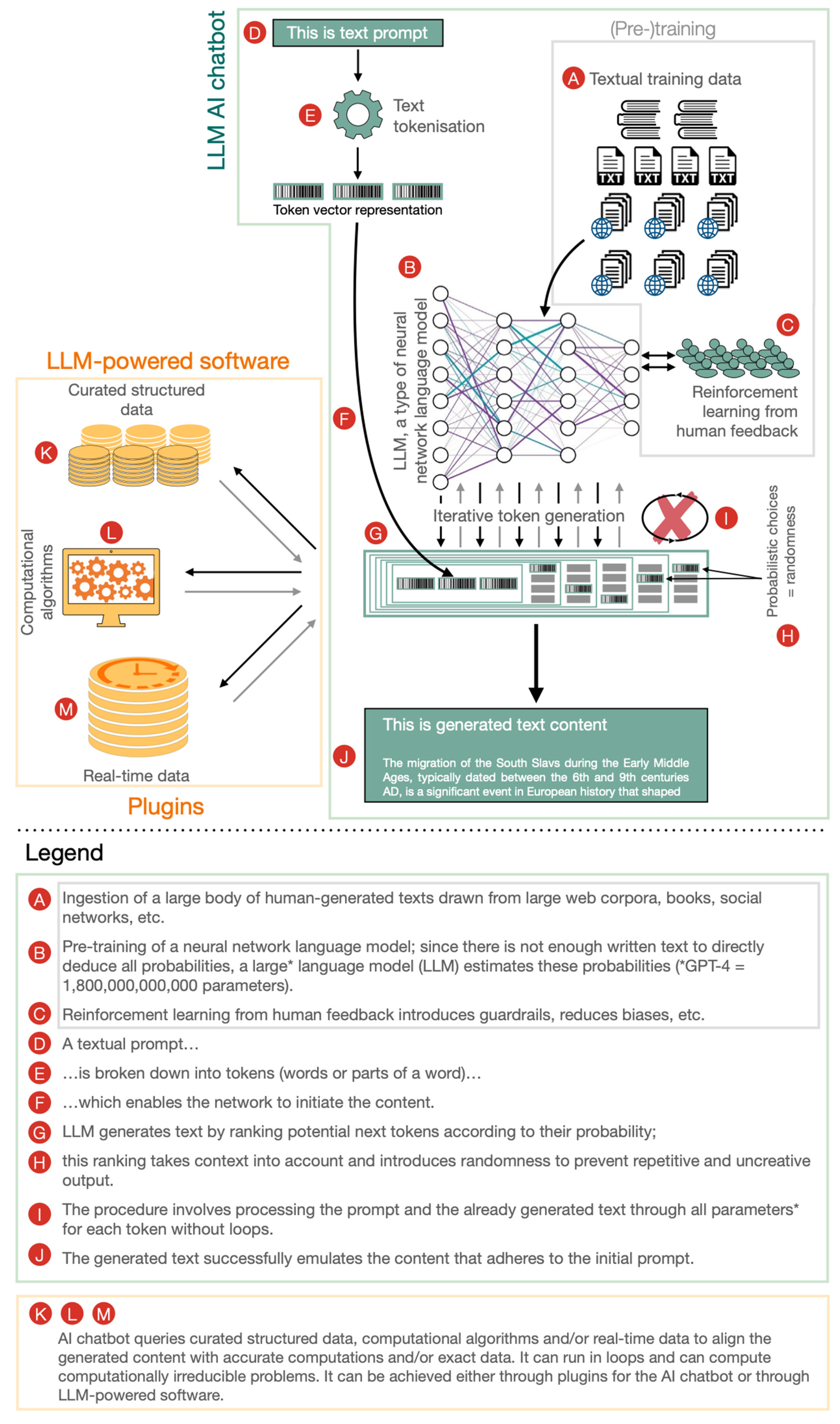
Future Internet, Free Full-Text

OpenAI Launches Superalignment Taskforce
de
por adulto (o preço varia de acordo com o tamanho do grupo)







